Sun's network file system
‘Sun’s network file system’ is a chapter in the OSTEP book by Remzi and Andrea Arpaci-Dusseau that describes the Network File System (NFS) protocol developed by Sun in 1986. More specifically, it describes the NFSv2 protocol. NFS is an early example of a distributed file system and serves as a case study in the early thinking around distributed file systems (and distributed systems in general).
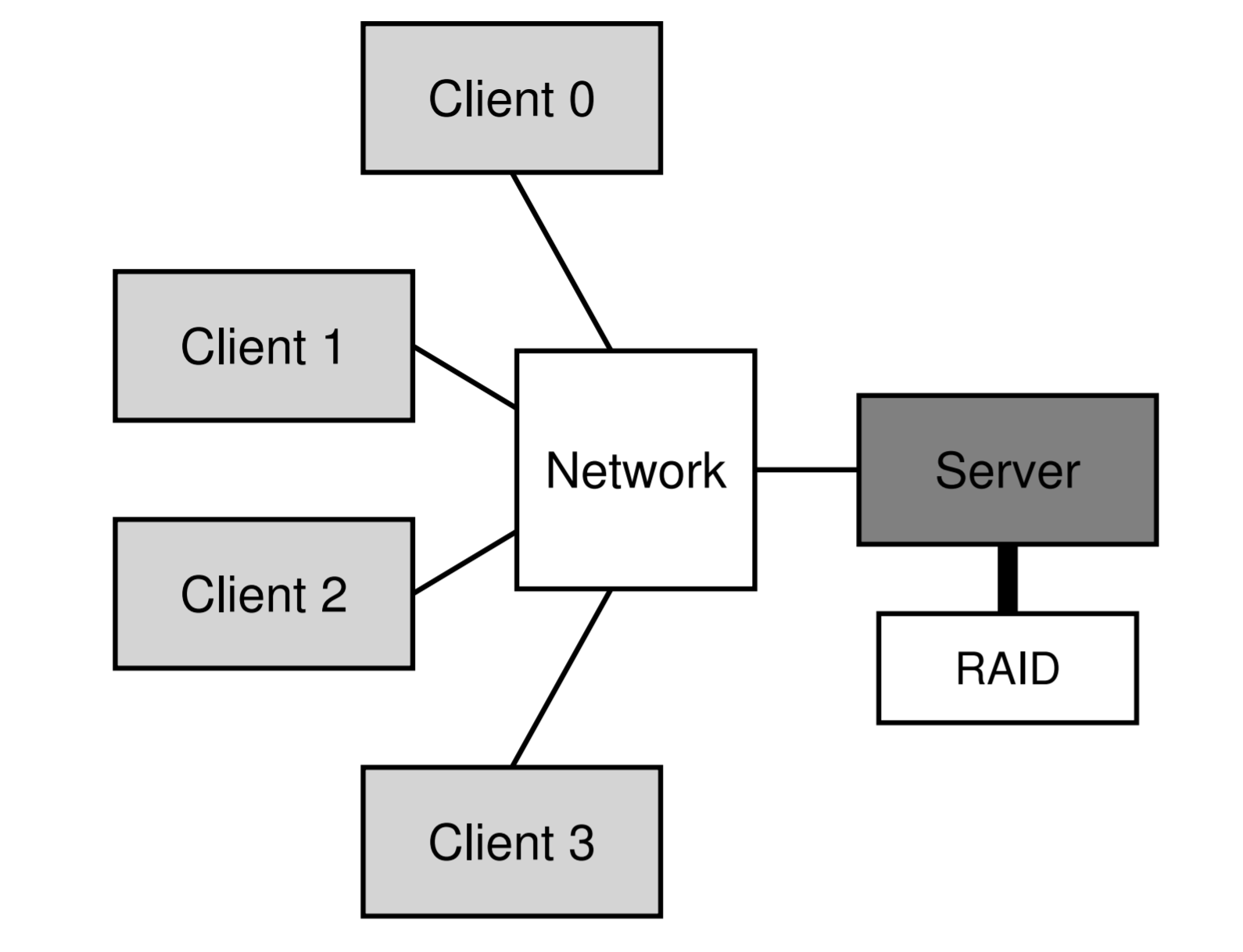
The need for distributed file systems: The primary motivation for a distributed file system is sharing, i.e., the ability to access a file from multiple machines called clients. These clients access the files that are stored on one (or a few) servers. Another advantage of storing files on a centralized server (as opposed to on each individual client) is the ease of administration. Administration includes things like backing up the data, enforcing quota across users, and security (the chapter notes security as a different aspect than administration, but I consider it to be a subset of administration in general).
A primary requirement for any distributed file system (like NFS) is to make its usage transparent to applications. Transparency implies that the client applications should be able to access data from the distributed file system in the same way as they access it from their local file system. One way to think about the requirement is that local file systems (and applications using local file systems) existed before distributed file systems and having transparency is a way to make distributed file systems backward compatible, thus helping their adoption.
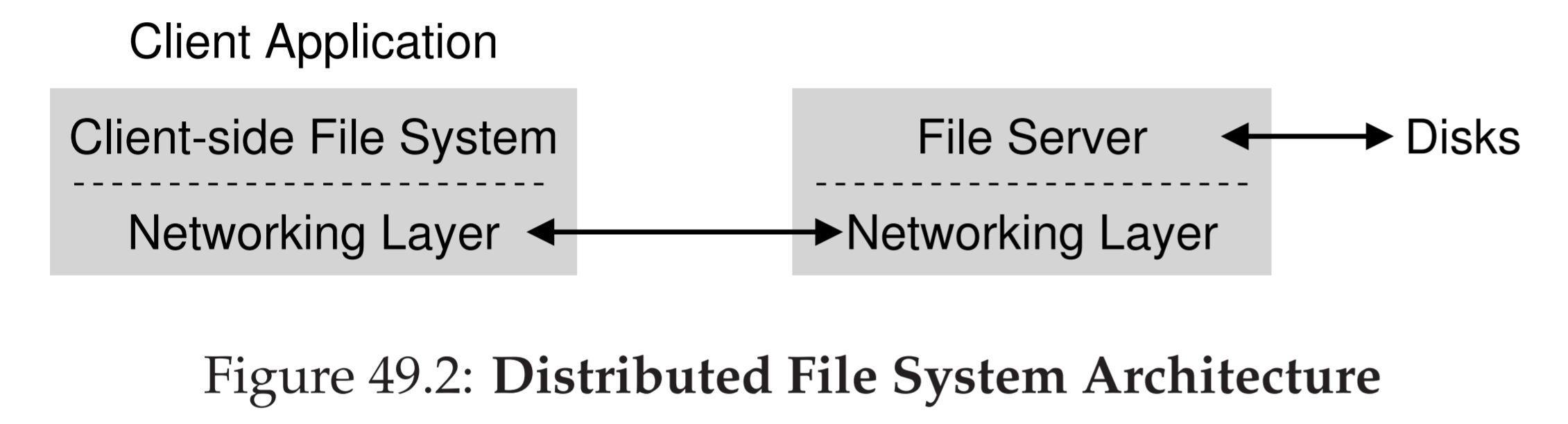
To enable transparent access to data from a distributed file system, NFS (and other distributed file systems) employs a client-side file system that acts as a go-between the client applications and the server-side file system. The client-side file system translates the applications’ local-file-system-like requests to the appropriate calls to the server-side file system. Sun’s NFS defined an open communication protocol for the server and client file systems. In addition to Sun’s implementation of their client and server file systems (together, the distributed file system), the open protocol enabled other vendors to implement their distributed file systems. The cross-vendor interoperability, thanks to the open protocol, was one of the reasons for NFS’s success and wide adoption.
NFS’s design goal: The main goal for NFS designers was to have fast and simple crash recovery for the file server. This is a meaningful goal because a server failure makes the filesystem unusable for all the clients, in contrast to a client failure that only affects the client.
Statelessness: The key to a fast and simple crash recovery (for anything in general, but for the file server in this case) is statelessness. Statelessness, as the name suggests, refers to the property that the file server does not store any state. State refers to any information that needs to be stored durably, i.e., information that needs to be recovered after a failure. If the file server is stateless, it does not have to spend any time recovering any information (recall that ensuring data is recoverable requires crash-consistency, which is challenging) and can simply start processing requests from client-side file systems after recovering from a failure.
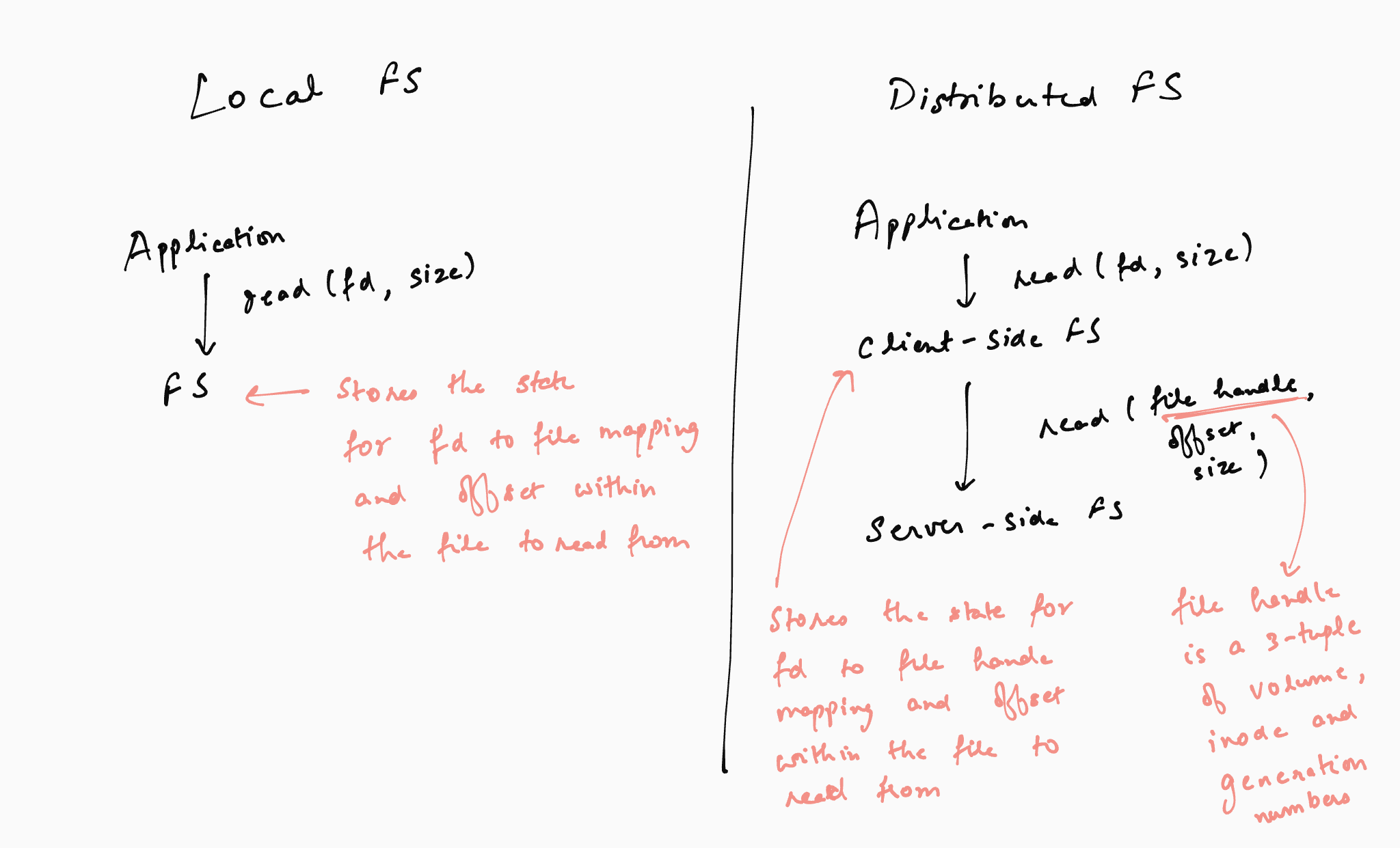
For a concrete example of file system state, consider that a client application opens a file and reads 1KB of data from it. After processing the read data, the client reads the next 1KB of data from the file. The way this works in a local filesystem (like FFS or LFS) is that the application receives a file descriptor (basically an integer) when it opens the file. It uses the integer to make the first read request to the file system. The file system returns the read data and stores a file pointer (storing the offset into the file) at 1KB. Next, the application requests the next 1KB of data of the file using the file descriptor. The filesystem knows where to start reading the data from based on the file pointer. In this example, the file system stores (at least) two pieces of information as state – the mapping of the file description to the file, and the file pointer storing the offset within the file. This is because if the file system were to restart for some reason, it would need this information to be able to serve future requests from the application – the application would only specify the file descriptor and it would be up to the file system to recognize the file and the offset to read/write from/to the file.
In order to make the server-side file system stateless, NFS relies on the client-side file to maintain the required state. The client-side file system uses this state to extract the relevant information for any application request and passes it on to the server-side file system. In the case of the above example, the client-side file system stores the mapping for the file descriptor and the file pointer. When the application makes a read request, the client-side file system uses this state and generates a read request for the server-file system which includes the file and the offset to read from (in addition to the number of bytes to read which is already present in the application request).
File handles: The next aspect of NFS design is about how a file is identified. The client-side file system needs to maintain a mapping of the file descriptor to the file. In case of a local file system, a file is identified by its inode number. NFS uses a file handle which is a tuple of three values – a volume number, an inode number, and a generation number. The volume number is used to identify the file system volume within which the file resides because one NFS file server can export multiple volumes (e.g., one file system volume per disk). The inode number identifies the file inode within the volume (similar to a local file system). The generation number is used to allow reuse of inode numbers in the server-side file system. To understand the need for generation numbers consider the following example. A client obtains the file handler for a given file A. While the client holds the file handle for A, file A is deleted on the file server and the server-side file system uses its inode number for a new file B. If the file handle only consisted of the volume and inode number, a new request by the client would end up accessing data from the new file B. To avoid such situations, the server-side file system increments the generation number whenever it reuses an inode number. Note that this problem does not arise in the case of a local file system reusing an inode because there isn’t a separate client- and server-side file system for a local file system. NFS could have also avoided the use of a generation number if the client- and server-side file systems were tightly coupled (e.g., if the server-side file system knew which client-side file systems held which file systems). However, this would require the server-side file system to hold this state, making it stateful. Instead NFS chooses to keep the server-side file system stateless by using generation numbers in the file handle.
Idempotent operations: Another aspect of simplifying file servers crash-recovery is to have idempotent operations. An operation is called idempotent if it has the same end effect irrespective of the number of times it is performed. For example, reading data from a file is idempotent because whether you read it once or twice or 10 times, the result is the same. Writing data to a file at a fixed offset is also idempotent. However, appending data to a file is not idempotent – if you append ‘a’ to ‘b’ once, you get ‘ba’, but if you do it twice you get ‘baa’.
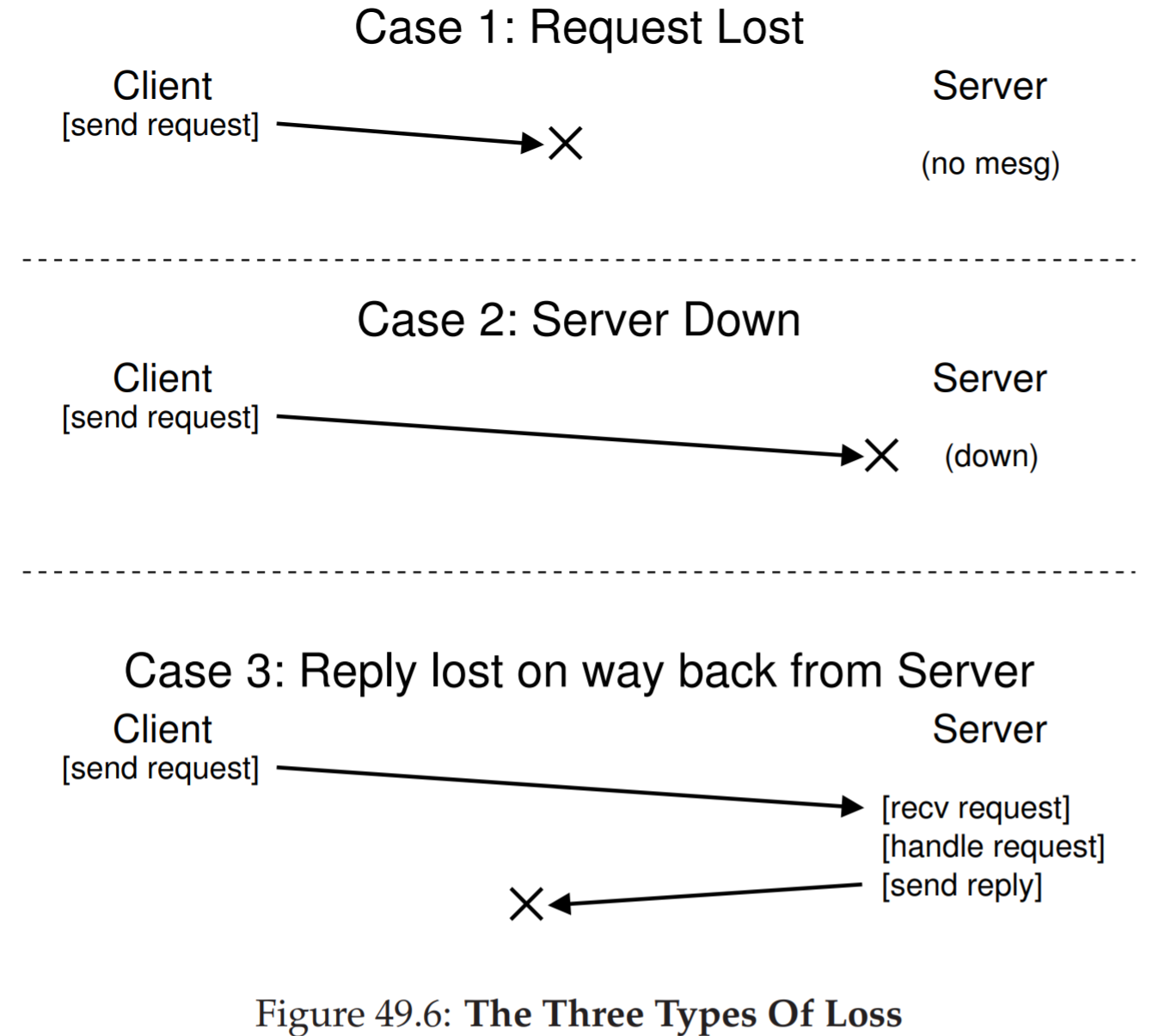
Idempotent operations offer a simple strategy for handling server failures – the client simply retries a request if it does not receive an acknowledgement of the successful completion of the request. The idempotency of operations ensures that this is safe. In addition to handling server failures (i.e., the server was not available to serve the request), the retry-if-not-acknowledged approach handles network failures as well (i.e., the request did not reach the server or the acknowledgement from the server did not reach the client because of a network packet loss). This simplicity offered by idempotent operations makes them a powerful tool for building distributed systems.
Caching: Caching is used almost ubiquitously in systems (distributed or otherwise) to improve performance and NFS is no exception. NFS clients cache the file blocks they read so that they don’t have to request the same block again from the file server (and incur the network round trip latency) in case the application requests it again. Further, when an application writes a block, the NFS client keeps it in its cache for some time before sending it to the file server. This is called write-back caching and it helps reduce the number of requests to the file system in case a block is updated repeatedly.
Although useful, caching often introduces the problem of cache-consistency. The cache-consistency problem is about identifying the most up-to-date data corresponding to a particular file or block when it can be write-back cached. For an example in the NFS context, if a client (say client-A) updates a file and keeps it in its cache without updating the file server, a subsequent read from a different client (say client-B) gets a stale copy of the file because the most up-to-date copy of the file is not available with the file server. This is referred to as the update-visibility problem. As another example, consider a scenario in which a third client (client-C) had read and cached a copy of the file even before client-A modified it. Even if client-A writes back the updated file to the file server, client-C would continue to use outdated data because it will read the data from its cache. This is referred to as the stale-cache problem.
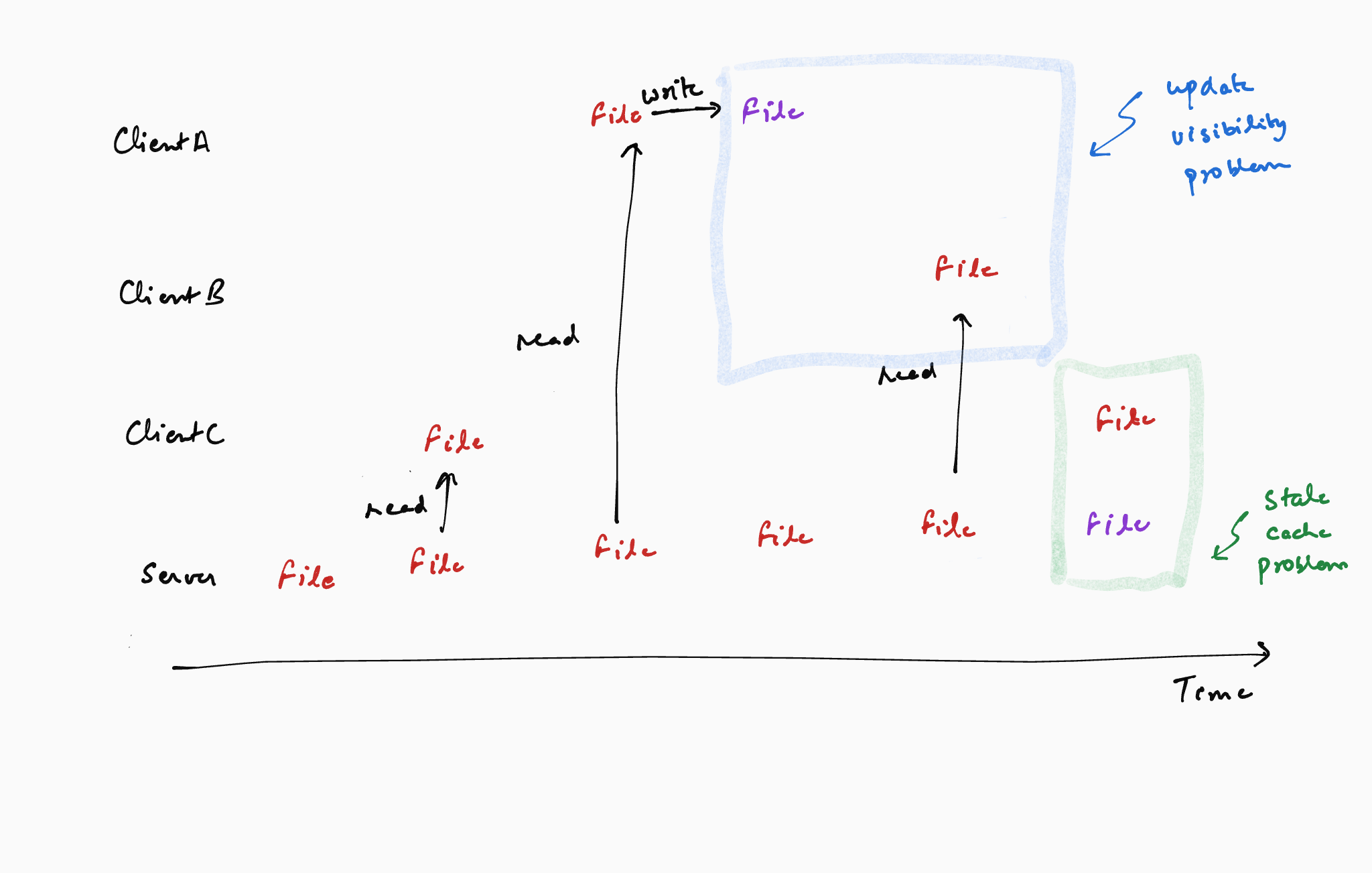
For the update-visibility problem, NFS chose the following design: whenever a file is closed on the client, it is flushed to the file server. This is referred to as the flush-on-close or close-to-open semantics. The flush-on-close semantic makes sense because closing a file is a reasonable logical demarcator. However, it can cause performance problems in case of short-lived files. For example, consider the process of compiling a large binary. This typically involves creation (and closing) of a bunch of temporary files that are discarded after a while. For such workloads, writing the temporary file to the file server is wasted work.
For the stale-cache problem, NFS chose the following design: before serving data from the cache, the client-side file system checks whether the file has been updated at the file server and serves the data only if it hasn’t been updated. However, doing this check for every read request on the client overwhelmes the file server. To address this, NFS introduces (surprise surprise!) an attribute cache to store the last updated time for each file on the client. The client-side file system checks the attribute cache before contacting the file server. Although the attribute cache reduces the number of requests to the file server, it leads to rather unpredictable behaviour – as each attribute cache entry has a time to live (TTL), applications could get old data rather arbitrarily depending on the TTL.
Concluding thoughts: NFS, as an example of an early distributed file system, showcases some key considerations for any distributed systems. In particular, it showcases the power of idempotency and statelessness for simplifying crash recovery. It also highlights the cache-consistency problems in distributed file systems and the need to thoroughly reason about the solutions’ semantics and trade-offs.