Design tradeoffs for SSD performance
‘Design tradeoffs for SSD performance’ by Agrawal, et al. was published in USENIX ATC 2008. This was right around the time when solid state disks (SSDs) were starting to become popular as a viable alternative to hard disk drives (HDDs). The paper describes the internal architectural and policy choices for SSDs and their performance tradeoffs.i
The building blocks of an SSD are flash packages, buffer memory, and a controller. Flash packages have an hierarchical organization — each flash package has one or more dies, each die consists of one or more planes, planes are composed of multiple (order of thousands) blocks, and blocks have multiple (order of tens) of pages. Pages are the smallest unit for a read or a write. Broadly, an SSD’s performance is affected by its architectural choices (parallelism and over-provisioning) and the design of its firmware (mapping, cleaning, and wear leveling policies), called the flash translation layer (FTL). The name derives from the firmware’s key responsibility of exposing a contiguous addressable space (akin to HDDs), hiding the underlying hierarchical architecture of the SSD and its flash packages. We will discuss the factors listed above and their (often interconnected) effect on SSD’s performance and cost.
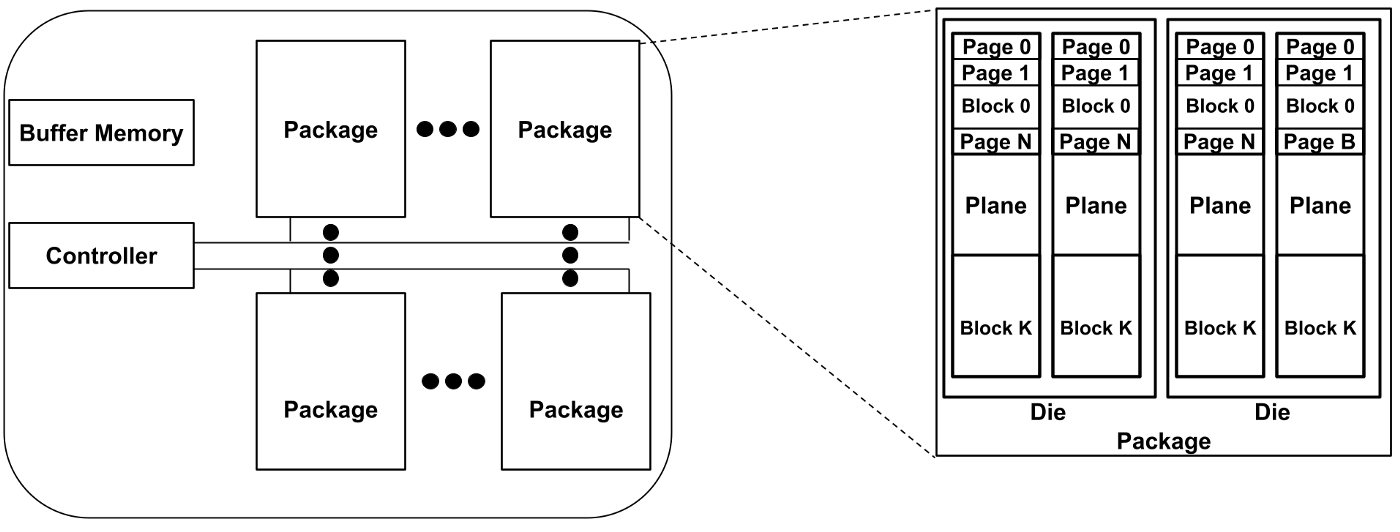
There is some inherent parallelism within each flash package. Consider the flash package described in the paper. It has 2 dies and both can operate in parallel. Each die has four planes and two planes can operate in parallel (i.e., plane 0 and 2 can operate in parallel, and so can plane 1 and 3). Operations within a plane are however sequential. Although the details of cross-die and cross-plane parallelism differ based on the specific flash packages, operations within a plane are always performed sequentially. In other words, a plane is the unit of parallelism. The inherent parallelism in flash packages enables the controller to increase throughput by spreading data accesses across planes and operating them in parallel.
The controller can also leverage parallelism across flash packages depending on the architecture of the SSD. Each flash package is connected to the controller via data and control lines. If the number of packages in a SSD is small enough (e.g., 2 packages) each of those can have independent data and control lines. This would enable the controller to operate the flash packages in parallel (in addition to the planes within the packages) to improve throughput. However, as the number of flash packages increase, the controller pins required for their lines increase. SSDs with a large number of flash packages use an architecture wherein multiple packages, called a gang, share these lines. Packages from different gangs can operate in parallel, but operations on packages within a gang are serialized (the exact serialization depends on the type of line sharing and is described in the paper).
Given an organization of flash packages in an SSD with certain parallelism, let us look at how the FTL exposes a contiguous addressable space. The first component of an FTL is its mapping policy that maps logical blocks to physical pages (which, recall, are the unit of reads and writes in an SSD). The logical block here refers to the addressable unit exposed to the host and is unrelated to the physical flash blocks. This unfortunate nomenclature of logical blocks is carried over from HDDs and is a commonly acknowledged point of confusion that persists nonetheless.
Serving read requests for logical blocks is fairly straightforward — the FTL looks up the physical page that contains the requested block’s data, reads the page, and returns the data to the host. Serving write requests is a more involved process. This is because data in a page cannot be updated-in-place (overwritten) after a write. This peculiarity is a characteristic of the underlying storage medium: NAND flash. Once a page has been written to, it must be erased before it can be written to again (kind of like a whiteboard). To make things even more interesting (or … complicated), the granularity of an erase is an entire block rather than a page. The typical latency for erasing a block is a few milliseconds, which is orders of magnitude higher than the latency of a typical read (tens of microseconds) and write (hundreds of microseconds). Block erases make in-place updates to pages prohibitively expensive, especially given that the FTL would need to read and write not-to-be-updates pages to make sure that their data is not lost. To reduce the critical path write latency, the FTL writes the data to a new empty (erased) physical page for each write request, updating its map accordingly.
Given the out-of-place updates in SSD, what happens if the host wants to update data in a logical block in an SSD at full capacity (i.e., with all logical blocks already written-to at least once)? To handle such scenarios, SSDs have over-provisioned capacity. This means that the addressable space that the FTL exposes to the host is less than the actual capacity in an SSD. Over-provisioning increases the cost of an SSD, but is critical for an SSD’s functioning. Moreover increasing the over-provisioned space also improves performance by improving the FTL’s cleaning efficiency, as discussed below.
Cleaning is the process of garbage collecting invalid pages (i.e., pages with out-of-date data). To clean a block, the FTL moves the data from the block’s valid pages to other physical pages before erasing the block and making it available for writes. The work required for cleaning is proportional to the number of valid pages in a block, and the FTL tries to delay block cleaning to accumulate invalid pages. SSDs with more over-provisioned space can delay cleaning for longer and thus achieve higher cleaning efficiency.
The choice of cleaning policy for an SSD is not straight-forward. The seemingly obvious choice of a greedy policy (i.e., clean blocks with maximum number of invalid pages) is challenged by another peculiarity of SSDs that the FTL has to take into account. Each physical block in a flash package can undergo only a fixed number of erases before it becomes unusable. This is referred to as wearing out of the block. If all the blocks in an SSD wear out, the device reaches its end-of-life. However, even if a fraction of the blocks wear out while other blocks have remaining lifetime, the SSD becomes unusable because it loses its over-provisioned space. This could be the case with a greedy cleaning policy for a skewed workload wherein some logical blocks are hotter (more frequently updated) than others — which is often the case in real workloads. Thus an additional responsibility of the FTL is to make sure that the blocks wear out at a roughly equivalent rate. This is called wear leveling.
In all of the above discussion, we have also made a simplifying assumption that the logical block size is the same as the physical page size. However, this need not be the case. In fact, having a block size that spans multiple pages offers certain performance advantages. The first is that it reduces the size of the mapping table that the FTL has to maintain. Smaller mapping tables improve performance because more entries can be cached on the limited on-chip buffer memory. Second, if a logical block spans multiple pages, these pages can be spread across multiple parallelly-accessible units (flash packages or planes) to increase throughput by accessing them in parallel.
The paper discusses these and other trade-offs in more detail. Over the years, researchers and practitioners have explored SSDs in much more detail, uncovered even more intriguing effects of SSD design choices, and proposed optimizations. I’ll end this summary with a note from the paper that “SSD performance and lifetime is highly workload sensitive, and that complex systems problems that normally appear higher in the storage stack, or even in distributed systems, are relevant to device firmware.”