File system design for an NFS file server appliance
‘File System Design for an NFS Server Appliance‘ by Hitz, et al., was published in the USENIX Winter Technical Conference in 1994. The paper described the Write Anywhere File Layout (WAFL) file system used by NetApp. NetApp is one of the largest storage providers today and its storage appliances and cloud product still use the WAFL file system at their core (along with many improvements over the years). WAFL organizes data in a tree structure and uses copy-on-write for data updates, which enables it to improve its write performance and efficiently implement crash-consistency. WAFL also introduces a critical feature of production storage, namely, snapshots, and in doing so, also circumvents a challenging garbage collection problem.
WAFL’s data layout and organization
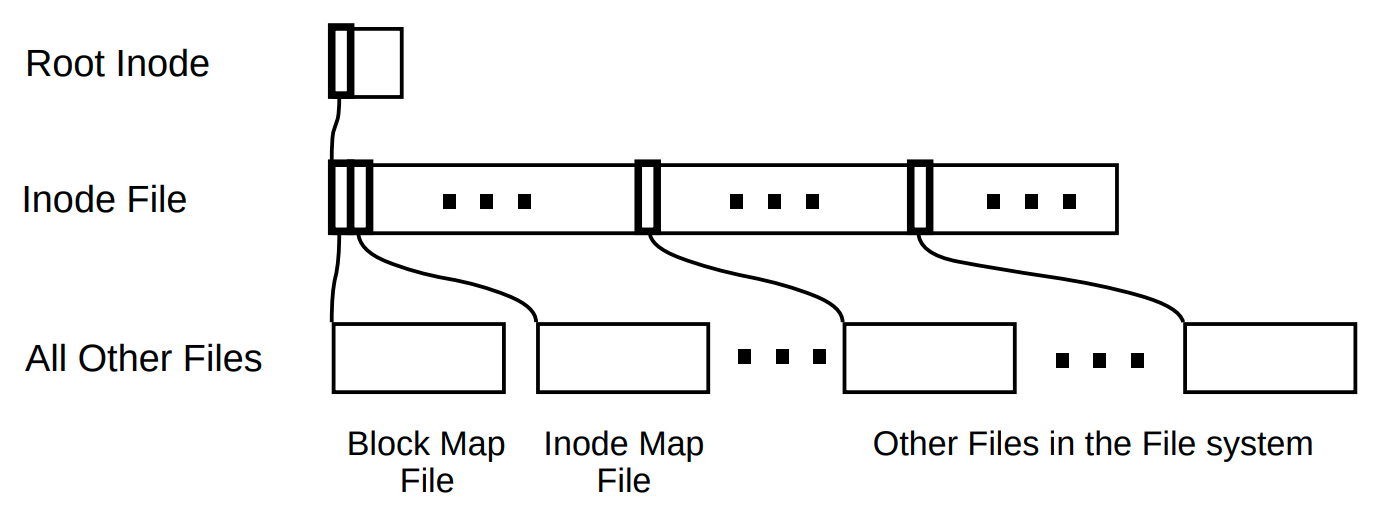
WAFL organizes its data as a tree of 4KB blocks and stores all of its metadata in files (in addition to the user data files). Conceptually, the WAFL tree has three components. The first component at the root of the tree is the root inode. This is the WAFL’s equivalent of the FFS or LFS superblock and is the inode for the inode file. The inode file is the second component in the WAFL tree and stores the inodes for all the (data and metadata) files in WAFL — it even stores a copy of the root inode, which enables some clever optimizations. The inodes in this inode file point to the (data and metadata) file blocks, which comprise the third component of the WAFL tree. These file blocks could contain user data, directory structures, or other metadata files (e.g., the files to store the inode and block allocation states).
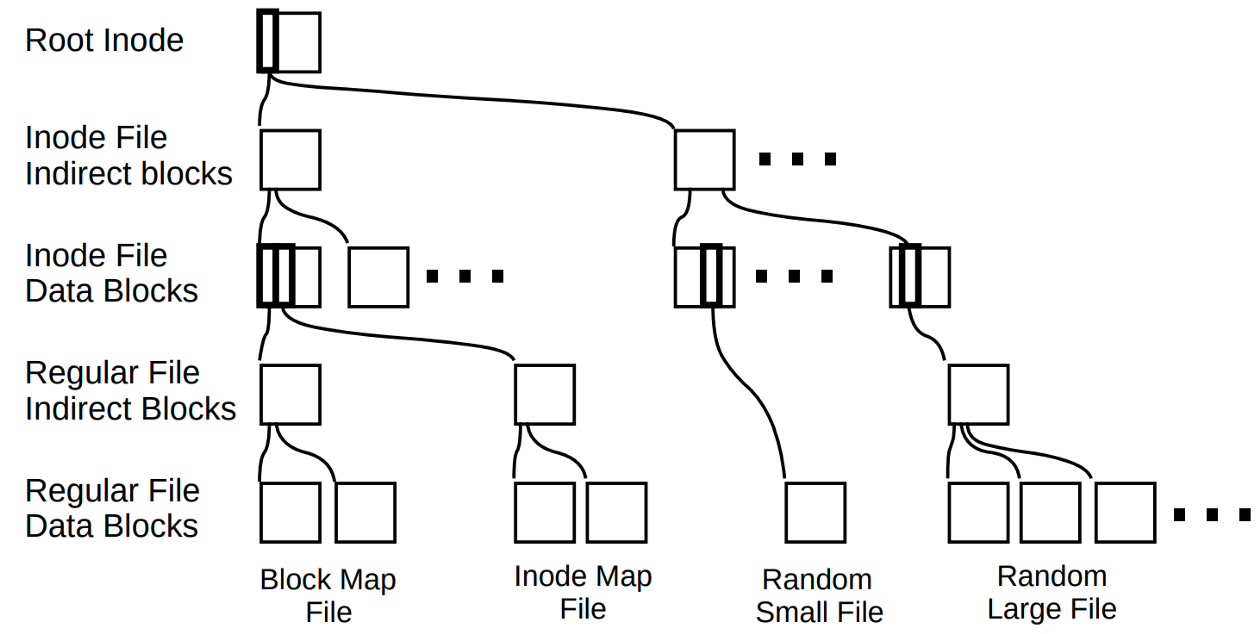
Although conceptually the inode file and the (data and metadata) file blocks are one level each in the WAFL tree, both of those can consist of multiple levels in the physical tree structure. Consider an inode in the inode file that points to the data blocks of a user file. The inode (which resides in a 4KB block) can contain only a fixed number of such data block pointers. For a large file that consists of more data blocks than the inode can point to, WAFL uses indirect blocks. The inode points to indirect blocks, and the indirect blocks point to the data blocks. WAFL’s use of indirect blocks for large files is similar to FFS, with one key difference. In FFS, an inode can consist of some direct data pointers and some pointers to indirect blocks. In contrast, in WAFL, all the pointers in an inode point to the same level, i.e., either to data blocks, or to indirect blocks. Thus as the file size increases, the levels in the physical WAFL tree also increase. Similarly, if the inode file size increases (e.g., to accommodate more files in the file system), the conceptually single level of inode file can also comprise multiple levels in the physical tree with the root inode pointing to indirect blocks that point to blocks in the inode file.
One of the advantages of storing metadata, particularly the inode and data block allocation state, as a file is that it enables WAFL to dynamically increase the file system size. A motivating usage scenario for the WAFL design was running it atop RAID arrays. If the underlying RAID array capacity were to increase because new disks were added, the file system capacity (in terms of the total number of blocks in the file system) also needs to increase. WAFL can dynamically increase the file system size by increasing the size of its inode and data block allocation files (to encompass more inode and data blocks).
The “write-anywhere” advantage of WAFL
WAFL uses copy-on-write for updating all of its blocks except the root inode. Copy-on-write is a general technique wherein updates are done out of place — upon an update to a logical block, the updated data is written to a new physical location as opposed to updating the block at the old physical location. Consider a WAFL application that wants to update a block of its file data. WAFL would write a new data block with the updated data instead of updating the old block. However, for this new data block to be accessible and part of the file system, the file’s inode (or its indirect block) must point to the data block. Here again, WAFL performs a copy-on-write, and writes the new inode (or indirect block) as a new block. If the inode file has indirect blocks, they are also updated out of place. As such, the copy-on-writes propagate up the tree. At the root of the tree however, the root inode is updated in place. This is the only block that WAFL updates in place. This is because WAFL needs to be able to find the root inode at a fixed location for the file system to function across reboots.
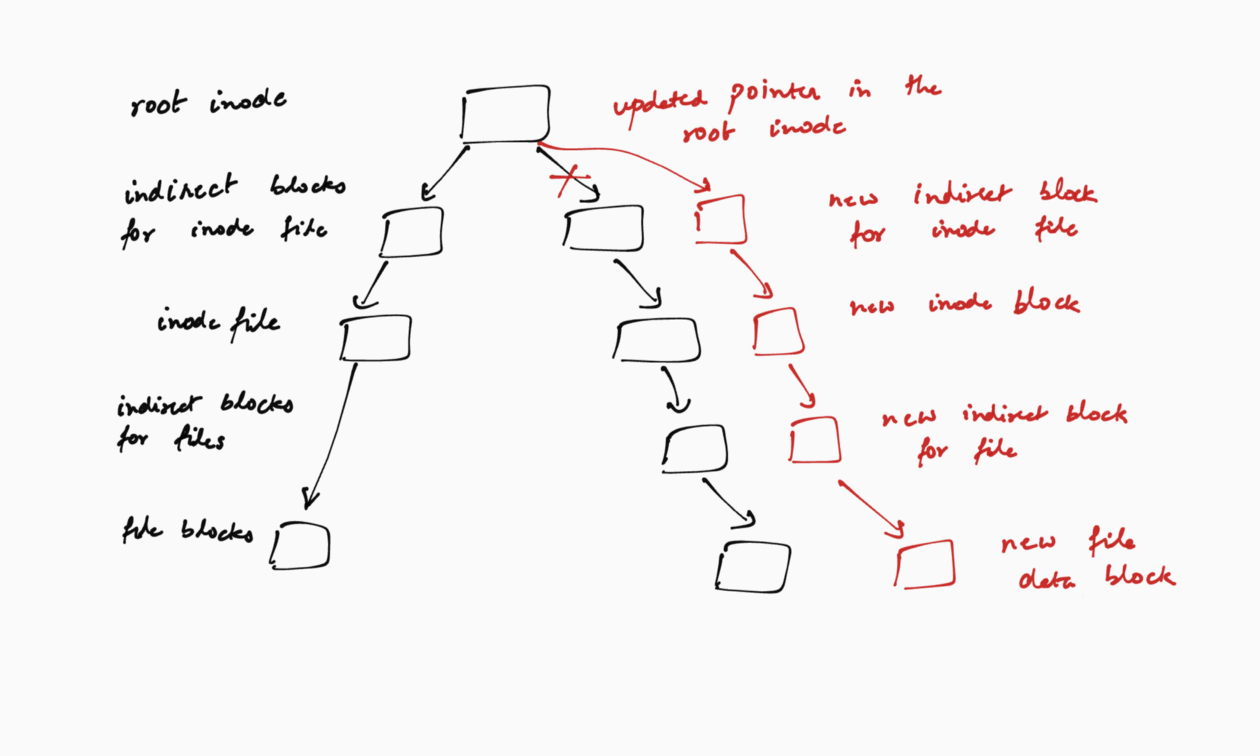
WAFL batches file system updates to improve its write performance. WAFL’s copy-on-write design turns every single write into a series of writes up through the WAFL tree. This makes file system updates slow. To improve write performance, WAFL caches updates from multiple application requests, and performs them as a batch. The time at which WAFL performs these batched updates is called a consistency point. Batching the updates amortizes the write cost across all the updates between two consistency points. For example, if all the data blocks for a file were updated via multiple application write requests between two consistency points, WAFL has to write the file’s inode just once for the entire file instead of once for each data block update. Other examples include file creation and deletion between two consistency points, or moving multiple files from one directory to another between two consistency points.
The batched updates and copy-on-write design enable WAFL to avoid the small write performance penalty of RAID arrays as well. Recall that small writes in RAID require a read-modify-write for the redundancy information (e.g., parity block in RAID-5). WAFL tries to avoid this small write penalty by writing an entire RAID stripe at a time. This is possible because when WAFL has to perform an update, it has multiple blocks to write (because of batched updates) and it can write them anywhere (because of its copy-on-write design).
Crash consistency in WAFL
WAFL’s copy-on-write design also offers an elegant solution for crash-consistency. Consider the point at which WAFL decides to update the file system. WAFL will write multiple new blocks to the file system that are inter-related to each other (e.g., a new file would have a new data block, new inode, new directory entry, new inode for the directory entry). However, none of these are part of the file system until the in-place update of the root inode because the root inode continues to point to a tree consisting of the old blocks. Thus the only requirements that WAFL has to enforce to ensure crash consistency is that (i) all the new blocks are written to the disk or RAID array before the root inode is updated, and (ii) the update to the root inode is atomic. Both the requirements are easy to enforce (e.g., using a checksum to atomically update the root inode, although the paper does not specify what WAFL does). With these two, once the root inode is updated, the file system is atomically updated (because the new root inode points to a tree with new blocks).
WAFL uses non-volatile RAM (NVRAM) to ensure that it does not lose the updates between two consistency points. NVRAM essentially consists of a battery backup that powers the volatile RAM for long enough to write out its data to disk, essentially making it non-volatile. Instead of using NVRAM to hold all of the updated cached blocks, WAFL stores the application requests it serves between any two consistency points in NVRAM. This is referred to as logical logging, as opposed to physical logging. For example, in case of a file move from ‘/foo/bar’ to ‘/baz/bar’, physical logging would require logging the inode for ‘bar’, the directory entries of ‘/foo’ and ‘/baz’, and the associated indirect blocks and inodes. In contrast, with logical logging, WAFL only stores the logical application request, i.e., file move request. In case of a sudden power failure, WAFL loads the most recent version of the persistent file system using the last successfully completed consistency point, replays all logical requests from the NVRAM, and then starts and completes a consistency point (to commit these operations).
A consistency point comprises the results of thousands to millions of operations — typically several GB of memory — and can take a few seconds to complete. During this time, WAFL continues accepting incoming operations. This is accomplished by double-buffering: a consistency point is started whenever one-half of the NVRAM is consumed to log incoming mutations. (It can also be started if WAFL accumulates a large enough fraction of updated blocks in the in-memory cache because of the application requests.) During the time of one consistency point, WAFL consumes the other half of the NVRAM and a remaining fraction of the memory to accept and process application requests for the next (and yet-to-be initiated) consistency point. The rate of consistency points is paced just right. Too fast, and it steals CPU and IO capacity away from processing incoming operation, which negatively impacts client-visible latency. Too slow, and WAFL runs the risk of exhausting the other “buffer” (other half of the NVRAM or too much memory) before the consistency point completes.
Snapshots — solving the garbage collection problem with a feature
WAFL solves the problem of garbage collecting old blocks by turning it into a feature wherein users can access old data via snapshots. The copy-on-write design of WAFL generates blocks with outdated data and WAFL needs to reclaim them so as to not run out of space. This is the same challenge that LFS also faces, which also uses copy-on-write (however, LFS does not “write anywhere”, but rather always writes sequentially). WAFL addresses the problem of garbage collection by introducing snapshots. Snapshots are point-in-time file system images that enable the users to access old (deleted or updated) data. By allowing access to old data, WAFL eliminates the need to delete old data immediately. Instead, it keeps the old data around for a predetermined period of time (offering access to it via snapshots) and garbage collects it later with minimal overhead.
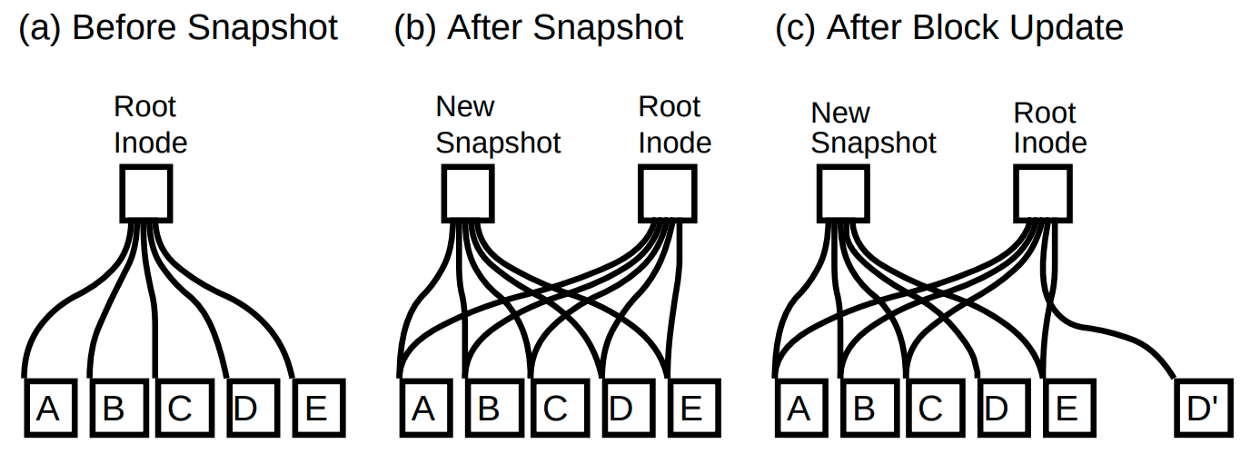
The copy-on-write design of WAFL enables efficient snapshots. At a consistency point, before atomically updating the root inode, WAFL creates a copy of the soon-to-be-old root inode. This copy of the root inode points to the tree with the old blocks, essentially serving as a snapshot with a point-in-time file system image corresponding to the last consistency point. WAFL keeps these snapshots around for a predetermined period of time. The challenge in keeping these around, however, is to avoid reusing the old blocks until the snapshot is deleted, i.e., the reverse of the garbage collection problem. To that end, WAFL uses a 32-bit entry to store the allocation state of the inode and data blocks (which are stored in the inode and data block map files, respectively). Each bit in the 32-bit entry identifies whether the block is part of the current file system image or some previous snapshot. This is in contrast to the single bit that FFS used to identify whether a block is part of the file system or not. WAFL updates the per-block 32-bit value whenever it creates or deletes a snapshot. Only when all the bits are 0 is a block eligible for reuse in WAFL. The tracking the allocation states of data blocks has since been redesigned to work much more efficiently and to support 1000’s of snapshots.
It is interesting (and mind boggling) to think about the combination of WAFL’s two key design choices: copy-on-write and everything-is-a-file. For example, the per-block 32-bit allocation states are themselves stored in the block allocation map files and so is the snapshot metadata like the location of the snapshot root inodes. All of these metadata files are also updated using copy-on-write. Interestingly though, the copy-on-write technique itself makes things work seamlessly. A snapshot’s root inode precisely captures the point-in-time image just because of the way a snapshot is created at a consistency point.
Concluding thoughts
WAFL has been ahead of the curve in many aspects. The paper emphasizes the benefit of disaggregating storage into specialized appliances accessible over the network, which is a popular architecture for modern storage systems. Snapshots are a common production storage feature today, and are almost always implemented using copy-on-write techniques (although, WAFL itself borrowed the technique from the database world). WAFL also demonstrated the benefits of co-designing multiple storage components (e.g., the file system and RAID). Although there is a continuous back-and-forth on co-designing vs layered abstractions for systems in general, WAFL continues to co-design the many storage components with great commercial success.
I would like to thank Ram Kesavan for his contributions and feedback on this post.