Metadata update performance in file systems
‘Metadata update performance in file systems’ by Ganger and Patt was published in the first Symposium on Operating Systems Design and Implementation (OSDI) in 1994. The paper proposed one of the many solutions to the problem of crash-consistency of file system metadata. We will begin this summary by describing the problem of crash consistency in file systems. We will then discuss some of the commonly used solutions for crash-consistency circa 1994. We will end with a discussion about the generality of the crash-consistency problem, highlighting its importance. As such, this post is based on multiple papers [1, 2, 3, 4, 5, 6] that help discuss file system crash consistency and covers more than just the soft updates solution proposed in this particular paper. Nevertheless, this post is titled the same as the paper because the paper title captures the essence (and it might have something to do with the lead author being my PhD advisor too :))
The crash-consistency problem in file system
At its core, the crash-consistency problem is the following: any given change to the file system can lead to changes in inter-related on-disk data structures, and these data structures need to be kept consistent at all times for the correct functioning of the file system. There are multiple aspects to this admittedly complex statement, so let us discuss them one-by-one.
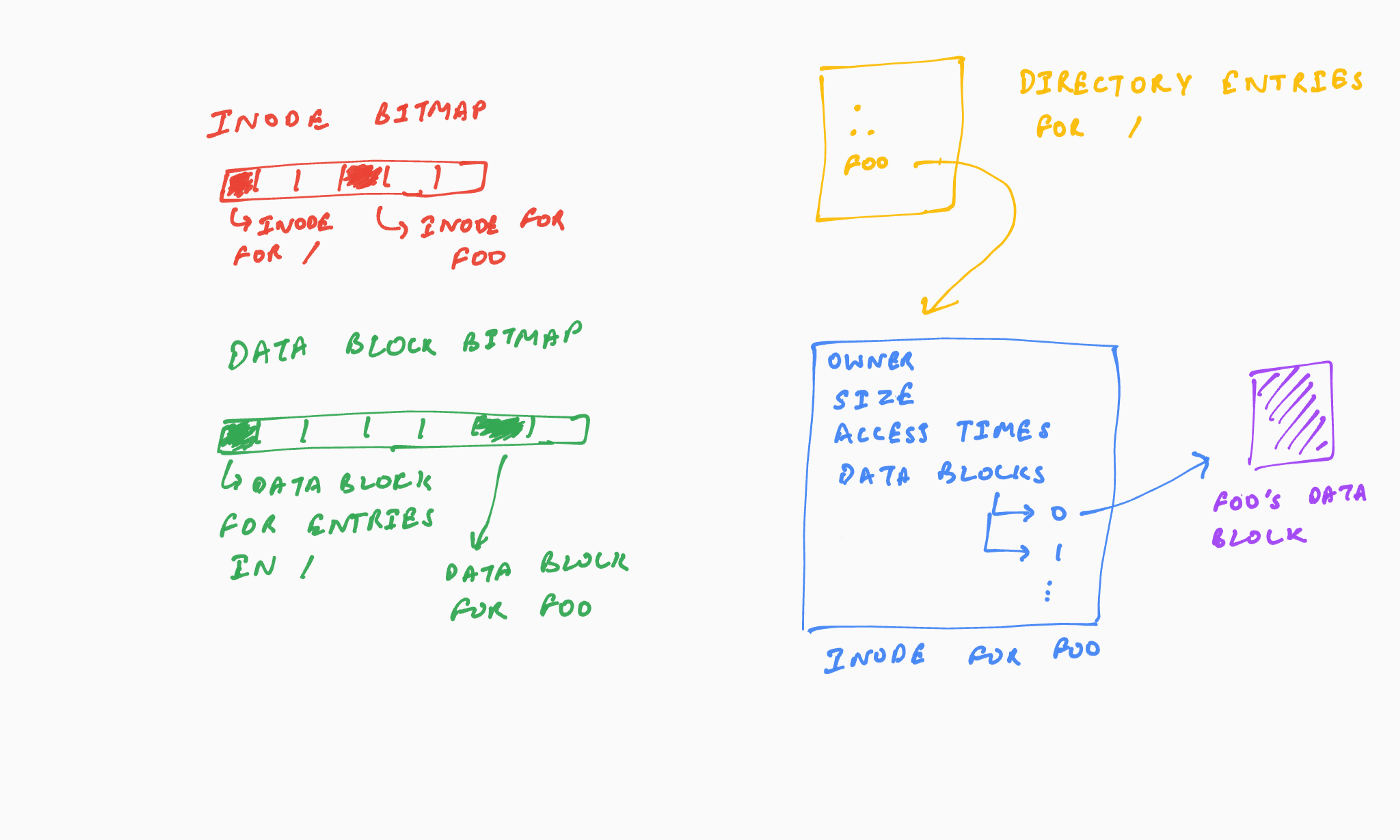
First, a file system consists of multiple inter-related on-disk data structures. As an example, the fast file system (FFS) consists of the superblock, inodes, data blocks, and bitmaps to store which inode and data blocks are free or allocated. For any given file, its inode points to its data blocks (with potential indirect blocks and pointers), a directory points to this file inode, and the bitmaps store the information that the file inode and its data blocks are allocated and hence not available for future allocations. All of these data structures are inter-related in the sense that they all relate to the same file.
Second, the inter-related data structures together determine the overall file system state, and as such, should be consistent at any point of time. Consider, in the above example, the effect of the data structures being inconsistent. For example, if the inode points to a data block, but the bitmap shows that the data block is free, which of the two should be trusted. As another example, if an inode is marked allocated in the bitmap, and the inode points to a data block, but no directory points to this inode, does the file exist in the file system? Inconsistencies across the data structures leave the file system in an indeterminate state.
Third, changes to the file system often require changes to multiple of the inter-related data structures. Consider the changes required for writing a block’s worth of data to the end of a file. It would require allocating a block and writing the new data to it, updating the inode to point to this data block and store the new file size and access time, and marking the block as allocated in the bitmap.
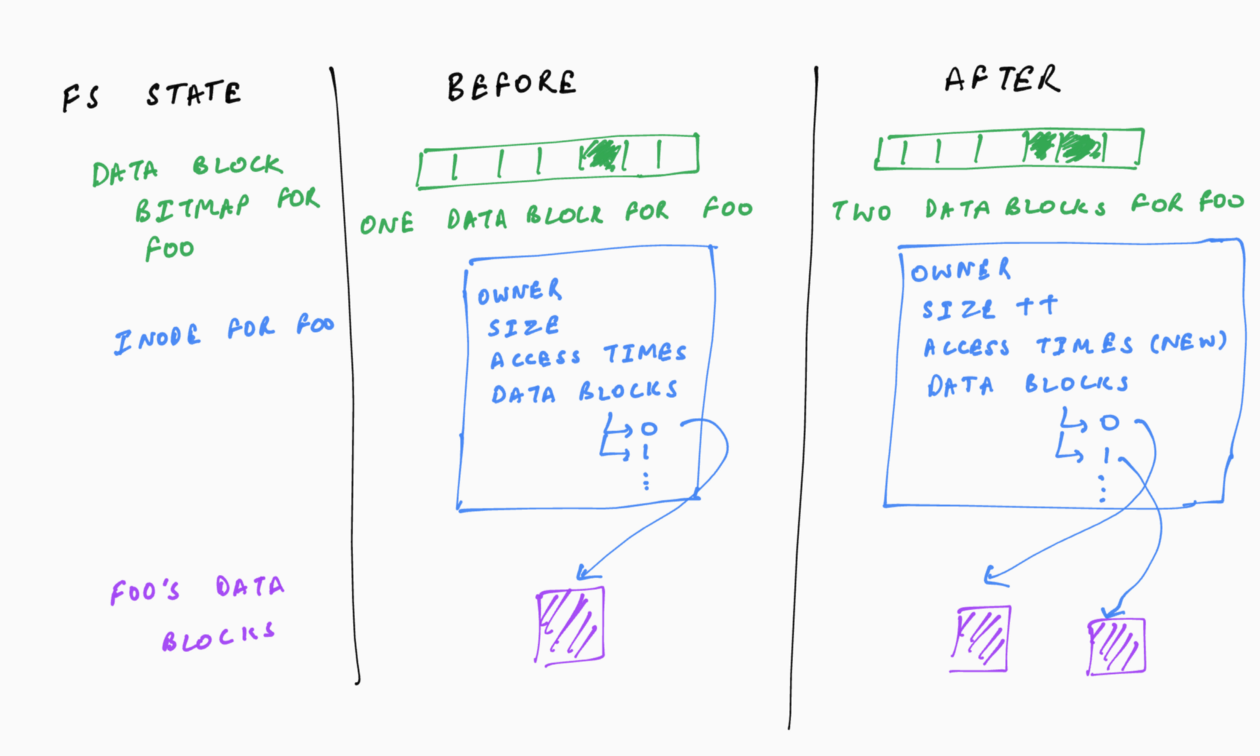
Combining the three points above, it is clear that updates to the file system state need be atomic. Atomicity refers to the changes being all-or-nothing. In the above example of appending to the file, atomicity would require all or none of the changes (data block, inode, bitmap) to be present on the on-disk data structures.
The crash-consistency problem is to make the file system state changes atomic in the face of failures such as power loss of operating system crash. Continuing with the above example, it is possible that the inode block is written to the disk but a power failure happens before the bitmap block is written, leaving the file system in an inconsistent state. The on-disk data structures are spread across different blocks, but disks (HDDs and SSDs) offer atomic updates guarantees only at a single block granularity. Thus, it is possible that only some of the updates related to a file system state change make it to the disk before an unfortunate failure, leaving the file system in an inconsistent state.
The problem of crash-consistency becomes even more challenging when the file system uses in-memory caches for performance. The file system reads and writes from the disk via the in-memory buffer. Although the file system can perform writes synchronously, asynchronous writes often improve performance (e.g., because the process can proceed with computation while the disk access happens asynchronously in the background). Asynchronous write-back, however, makes crash-consistency even more challenging because the blocks (and hence, the on-disk data structures) can be written out in an arbitrary order.
Although the problem of crash-consistency relates to all the on-disk data, some file systems limit the scope of the problem by considering only the crash-consistency of metadata. Metadata here includes the superblock, data structures to store the allocated-or-not state of blocks (bitmaps in FFS), inodes, and directories, but not the user data. Because of this, the crash-consistency problem of file systems is also referred to as the metadata update problem.
The file system checker, FSCK
The fast file system (FFS) adopted a fairly simple solution for crash-consistency: it performed metadata updates synchronously, and used an offline file system checker (FSCK) to restore the file system to a consistent state upon reboot. The FSCK went over the on-disk data structures in multiple passes, checked their state, and made appropriate changes, potentially with the inputs of the system administrator. The checks included sanity checks, e.g., the block numbers should be within the min and max block number, as well as cross data-structure checks, e.g., data blocks pointed to in an inode must be marked allocated in the bitmap. FSCK also had some in-built restorative actions, e.g., if the inode and bitmap differed for an allocated block, the inode’s state generally prevailed.
FSCK, although simple, is not practical for large file systems. It requires reading all the blocks in the file system, and becomes unwieldy with large file systems.
Batteries!
An ingenious solution to the crash-consistency problem is to have battery-backed systems that can run for long enough for the file system to complete any ongoing metadata updates as well as write-back all of the in-memory cached blocks. The downside with batteries however is their cost and their reliability (what if the battery fails!?)
Journaling
Probably the most widely deployed solution for the crash-consistency is journaling, or write-ahead logging, which is a technique borrowed from database systems. Journaling involves writing the metadata changes to a log, or a journal, located at a fixed location in the file system before writing the changes to the actual on-disk blocks. Because the changes are written to the log, the file system can redo the changes using the log following a crash. In the example of appending to a file, the file system would write out the inode as well as the allocation bitmap blocks to the journal before writing it to the file system structures. So, if a crash were to happen after only the inode was written to the disk, the file system can read the journal and update the bitmap accordingly.
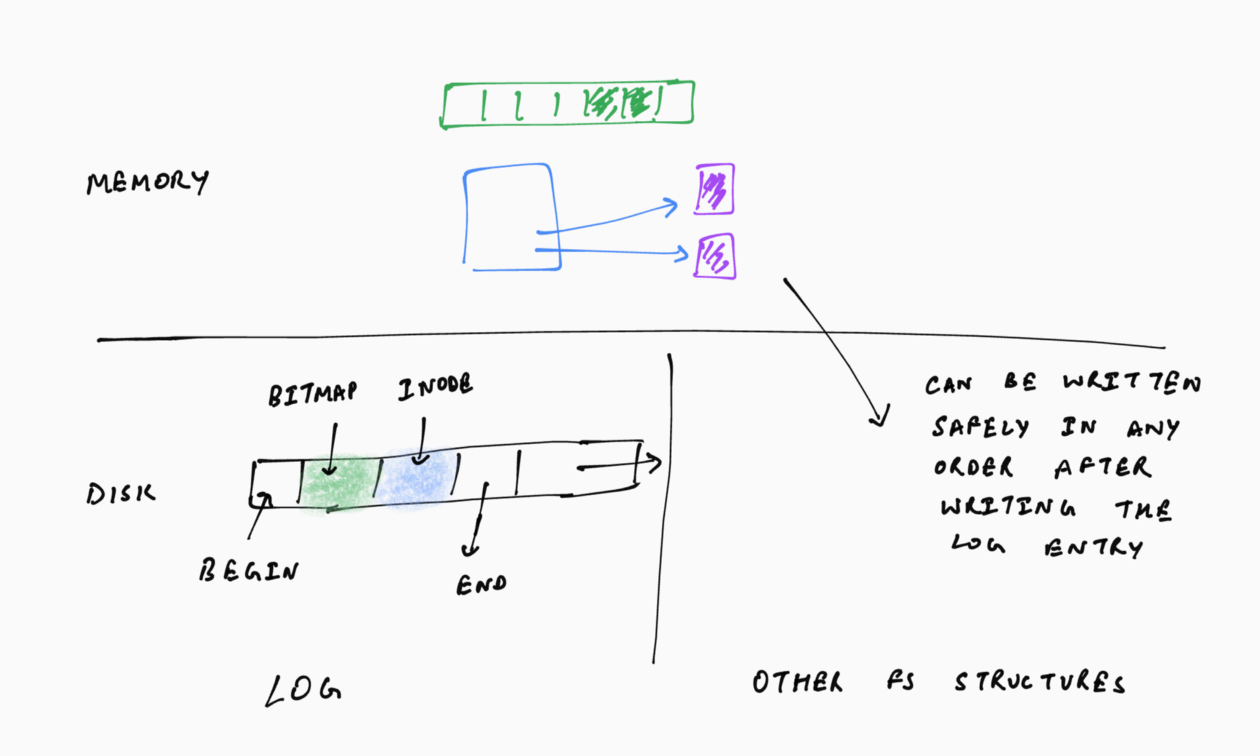
The write-ahead log consists of log entries for each file system state change. A log entry typically consists of a start block, the new (updated) metadata blocks related to a file system state change and an end block. The end block is written separately, after completing the write of the start and metadata blocks (which are written together) — this ensures that a log entry is considered completed only after all of the metadata blocks are committed to the on-disk log. Another approach for validating log entries is to have a checksum in the log entries (in the start and/or end block). Thus, irrespective of the order in which the log entry blocks are written, the entry would be considered valid only if the data matches the checksum.
Write-ahead logging has the nice property that the log is written sequentially, on the disk. To further leverage sequential writes, file systems often buffer multiple file system state changes in-memory, and write all of these changes to a single log-entry. This is known as group-commit. Group commits also enable multiple updates to the same metadata block to be grouped, reducing the number of times the block is written to the log. For example, if there were two append operations to a file, instead of having two log entries, each with its own copy of the file inode and allocation bitmaps, with group-commit, there would be only one log entry with one copy of the inode and allocation bitmap.
Periodically, the file system frees up space in the write-ahead log (for future log entries) by checkpointing the file system state. A checkpoint refers to a state wherein all the on-disk metadata blocks have no associated log entries. A naive way to checkpoint the file system state would be to pause all foreground file system activities and flush all of the cached metadata blocks. This, of course, is undesirable from a performance standpoint, and file systems are able to take checkpoints without quiescing the entire system. As such, the log is used as a circular buffer and the file system maintains a log start and end pointer — only the entries between these pointers are used to redo metadata operations after a crash.
The downside of journaling comes from two factors. First, it doubles the number of the metadata block writes (and even the data block writes if crash-consistency is maintained for the data as well). Second, although the writes to the journal are sequential, when intermixed with the writes to the file system data and metadata blocks (which themselves might also be sequential), the resulting access pattern is not sequential, which degrades performance. Some file systems use a small complementary disk that holds just the journal to avoid random writes to the disk.
Crash-consistency in the log-structured file system (LFS)
As promised in the post on LFS, I will discuss LFS’s crash consistency in this post. Recall that in LFS, all the data is stored in the log, and the log is always written to the disk sequentially.
The log in LFS is similar to the write-ahead log in a journaling file system, and its crash consistency procedure is similar to that of journaling file systems. LFS ensures that its segments are valid using a begin and end tag or a checksum-like approach. It also periodically checkpoints its data structures and stores them at a fixed location on the disk. Because the log is the only data source in LFS, LFS writes blocks in the log in an ordered fashion that allows recovery by reading the log. For example, when creating a new file, LFS would arrange the blocks such that the new file’s inode is written to the log before the directory entry for that file — this ensures that the directory entry points to a valid file.
LFS addresses the two problems of journaling based crash consistency — it does not double the writes and all writes are always sequential. However, the performance of LFS in general has always been a topic of debate because of its cleaning overhead.
Soft updates
The key idea of soft updates is to ensure that the on disk structures are written to in an order that always leaves the file system in a mostly consistent state. Here, I use mostly consistent to mean that although the data structures may have some minor inconsistencies (that can be fixed in a fashion similar to fsck), the file system can be used safely even without fixing those minor inconsistencies.
Consider our running example of appending a block to the end of a file. One of the ordering requirements that soft updates enforces is that the new data block must be written to the disk before the inode pointing to this data block is written. If this ordering is not enforced, the file system could potentially serve garbage data if a power failure were to happen after the inode write but before the data block write. However, the ordering can lead to a minor inconsistency wherein the data block is written to the disk but the inode does not point to the data block. Soft updates can use fsck to fix such inconsistencies after a reboot. Note that even without the fsck fix, the file system is safe to use because the ordering guarantees that all data blocks pointed to by the inode have already been written to the disk.
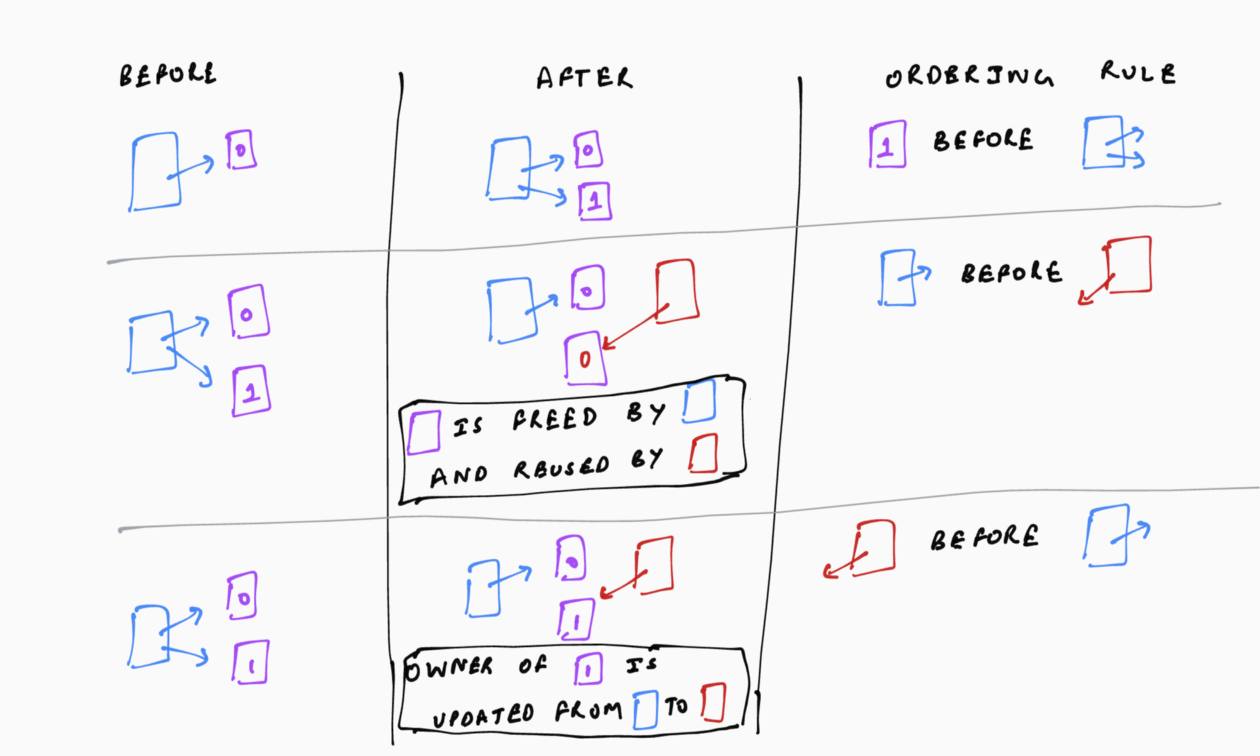
To ensure that the file system is always in a mostly consistent state, soft updates enforces the following orderings:
- The pointed-to structure should be written before the pointed-by structure. For example, the data block should be written to disk before an inode pointing to it, and a new inode must be written to disk before its corresponding directory entry. This ensures that the file system never accesses any garbage.
- All previous pointers to a freed structure should be written as null before the structure is re-used. For example, if a data block is freed as part of a file truncation, the corresponding file’s inode with the nullified pointer must be written to disk before the data block can be reused for any other file. If this was not enforced, the file system can incorrectly associate re-used resources with their previous owners.
- Write the new pointer to an allocated structure before removing its previous pointer. For example, when renaming a file, the new directory entry pointing to the file’s inode must be written before the previous directory entry is removed. This ensures that the structure is not left orphaned (pointed-to by neither the old nor the new owner) as part of the move.
To perform a file system state change, soft updates changes the in-memory copy of the data structures and adds auxiliary ordering information which is used when writing back the structures to disk. Consider the ordering requirement of writing a data block to disk before the inode pointing to the data block. Soft updates would update an in-memory copy of the data block and the inode pointing to the data block. It will also associate a data structure with the inode pointer that records the ordering dependency. If the file system decides to write the inode to disk, it will check the auxiliary structure to see whether the corresponding data block is already written to disk. If so, the inode write will proceed normally. However, if the data block has not been written to the disk, soft updates would revert the inode pointer back to NULL, write this old-state of the inode to disk, and then update the in-memory copy of the inode to point back to the allocated block. Thus the on-disk structures remain consistent (the inode does not point to an unwritten data block).
Soft updates maintains and enforces the ordering dependencies at a per-pointer level as opposed to a per-block level. A per-block level dependency tracking was indeed the first attempt of the authors, but they realized that it leads to cyclic dependencies (a single block can contain multiple dependency-causing structures) making them unwieldy.
The challenges in implementing soft updates has limited its adoption despite its impressive performance (particularly for metadata heavy workloads). Despite the simplicity of the rules, soft update implementations are non-trivial and require intricate knowledge of the file system data structures.
Generality of the crash consistency problem
The problem of crash consistency is rather ubiquitous in systems. It shows up whenever there is a caching layer in front of the durable storage layer. For example, distributed storage systems care about crash consistency when propagating changes from the client node to server nodes. Distributed and single-node databases systems care about crash consistency of multiple updates within a transaction. Crash consistency problems show up even within disks because of the presence of on-disk caches and the complex mapping data structures maintained by the disk firmware. Interestingly, the presence of on-disk caches also make it challenging to ensure that a write acknowledged by the disk to the file system was actually written to the persistent medium (disks are known to acknowledge writes as durable after committing them only to the on-disk cache, even when asked not to do so!). Not surprisingly, there are many crash consistency solutions, but they often draw inspiration from one of the basic solutions like journaling or soft updates (One prevalent basic solution, missing from this discussion, is shadow paging, which we will cover in a future post; this one is long enough as is :))
References
- ‘Metadata Update Performance in File Systems’, Ganger and Patt, USENIX OSDI 1994
- ‘Soft Updates: A Solution to the Metadata Update Problem in File Systems’, Ganger, et al., ACM Transaction on Computer Systems 2000
- ‘Logging versus Soft Updates: Asynchronous Meta-data Protection in File Systems’, Seltzer, et al., USENIX ATC 2000
- ‘The Design and Implementation of a Log-Structured File System’, Rosenblum and Ousterhout, ACM Transaction on Computer Systems 1992
- ‘FSCK: The UNIX File System Check Program’, McKusick and Kowalski, White Paper, 1996
- ‘Crash Consistency: FSCK and Journaling’, Arpaci-Dusseau and Arpaci-Dusseau, Operating Systems: Theee Easy Pieces (OSTEP) v1, 2018